|
I'm currently a postdoctoral fellow at the Institute of Data Science (IDS), University of Hong Kong, advised by Prof. Xihui Liu and Prof. Yi Ma. Before that, I obtained my Ph.D. from University of Science and Technology of China (中国科学技术大学) in 2023, supervised by Prof. Xueyang Fu and Prof. Zheng-Jun Zha. I also gained valuable experience working at International Digital Economy Academy (IDEA), Tencent ARC Lab, and Tencent Youtu Lab. Email / Scholar / GitHub / X (Twitter) |

|
|
My research centers on computer vision, graphics, and machine learning, including 3D and video generation, pedestrian and object recognition, and low-level vision. I am particularly interested in 3D generation of objects, avatars, and scenes, with the ultimate goal of creating immersive and fantastic digital worlds. |

|
Repurposing pre-trained 2D flow matching model for panorama generation, perception, and completion, enabling graphics-ready 3D scene creation. |

|
Leveraging implicit 3D scene representation to achieve robust background consistency and precise camera control for dynamic video generation. |
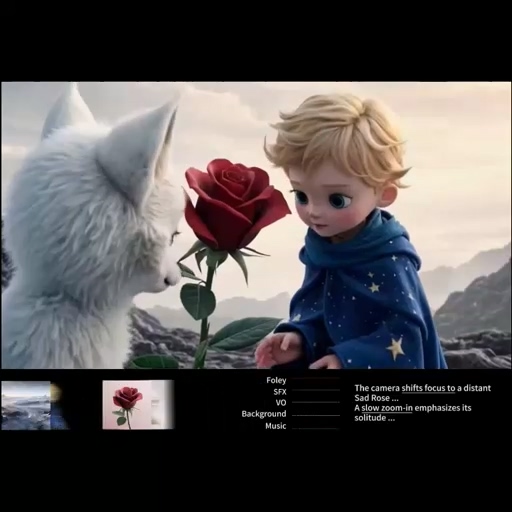
|
FilMaster pioneers AI-driven filmmaking by automating the entire pipeline with cinematic principles. |

|
Decomposing a 3D shape into complete, semantically meaningful parts. |

|
An iterative, self-correcting multi-agent collaborative framework for compositional text-to-video generation. |

|
Part-aware 3D object generation framework designed to achieve high semantic decoupling among components while maintaining robust structural cohesion. |

|
Foundational realistic world simulator capable of generating infinitely long 720p high-fidelity real-scene video streams with real-time, responsive control. |

|
RGB-D cubemap generation using pre-trained 2D diffusion and multi-plane synchronized operators, with applications in panoramic depth estimation and 3D scene synthesis. |

|
Expressive full-body 3D avatar generation from 2D diffusion using hybrid 3D Gaussian avatar representation and skeleton-guided score distillation. |

|
Integrating multi-view conditions into image and video diffusion models to generate controllable novel views for 3D object reconstruction. |

|
Zero-shot, multi-granularity 3D part segmentation using vision foundation models to learn scalable, flexible 3D features without label sets. |

|
Integrating multi-view conditions into pre-trained 2D diffusion models to generate controllable novel views for 3D object reconstruction. |

|
Analyzing the drawbacks of random timestep sampling in score distillation sampling (SDS) and proposing a non-increasing timestep sampling strategy. |

|
Utilizing texts as semantic guidance to further constrain the solution space of NVS, and generates more plausible, controllable, multiview-consistent novel view images from a single image. |

|
High-quality animatable avatar generation from texts via 3D-consistent occlusion-aware score distillation sampling, ready for 3D scene composition with diverse interactions. |
|
|
Website template from Jon Barron's website. |